Ollama's Qwen3-VL Introduces The Most Powerful Vision Language Model - Here's How It Works

Imagine pointing your phone's camera at the world, asking it to identify the dark green plant leaves, and asking if it's poisonous for dogs. Likewise, you're working on a computer, pull up the AI, and tell it to convert the tabular data into a graph — and the AI answers it all. All this is possible courtesy of "vision" capabilities of an AI model. And it seems we have a new kid on the block that is going to fare better at visual understanding when compared against the big boys like Google's Gemini, OpenAI's GPT-5, and Anthropic's Claude.
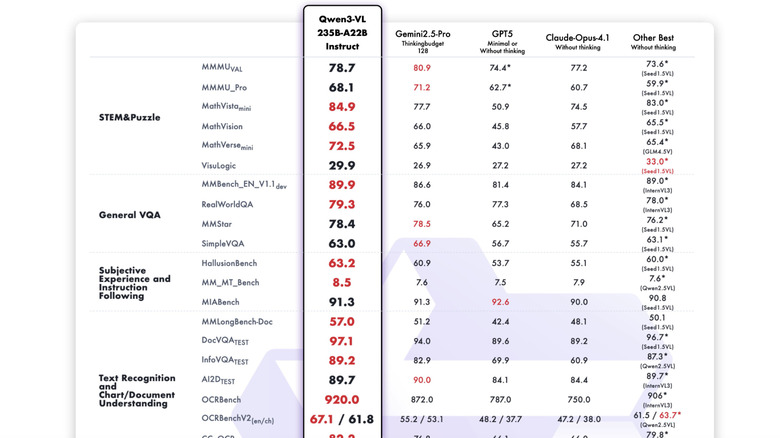
Now, before we go into the nitty-gritty of what it does well, how it works, and where it lags behind, here's something truly interesting. Alibaba is pushing its flagship model, the Qwen3-VL-235B-A22B, out in the open source domain, and it's now available via Ollama. That means developers can deploy it within their software freely, while also leaving the room open for modifications. Now, let's focus on the capabilities, some of which are truly impressive.

Qwen claims that the aforementioned model can turn images or videos into code formats such as HTML, CSS, or JavaScript. In a nutshell, what it sees can instantly be turned into programmable code. It also supports up to 1 million token input, among the best out there, allowing it to process two-hour videos or hundreds of pages of documents as input.
The model also offers a better understanding of object positions, viewpoint changes, and 3D spatial data. Then there are the Optical Character Recognition (OCR) capabilities, which allow the AI model to process text it sees in images and videos. The OCR chops of Qwen3-VL support 32 languages and are also touted to be capable of handling bad inputs with poor lighting, blue, and angled capture.
The working theory for real-world usage
The most impressive part about Qwen3-VL is the ability to control computers and mobile devices. Simply put, if you instruct it to book tickets for four people on Ticketmaster, the AI model will handle every step of the workflow autonomously. That means it will open a web browser, launch the site, fill in the instructions (number of people, seat preference, etc.), make the booking, and execute the task with an end-to-end approach. That's something impressive, though not entirely novel.

OpenAI offers an agentic tool called Operator that can handle tasks autonomously. Microsoft is also offering agentic capabilities in Copilot Studio, while Anthropic's "Claude computer use" also hopes to pull off autonomous workflows. The competition is obviously hot, but here's the core difference. Qwen is pushing its AI model in the open-source domain, while its competitors charge users for it. On top of it, the company claims that Qwen3-VL achieves "top global performance on benchmarks like OS World, and using tools significantly improves its performance on fine-grained perception tasks."
In a YouTube video, AI consultant Bijan Bowen pushed the Qwen vision model at multiple computer use scenarios, and it fared pretty well. He tasked Qwen3-VL with posting a comment in a specific Reddit community, had it write some stuff, and even ordered a car. Though it fared pretty well, the model still struggled with some rather mundane details, such as filling in the right ZIP code while purchasing a vehicle. Some of the demo scenarios shared on the Qwen blog are also pretty impressive. The speed, however, is the standout aspect. I've tried agentic tasks using other AI models for ordering groceries. Though they got the job done, they weren't quite as fast as the task execution pace of Qwen3-VL.