Photo Wake-Up AI Creates 'Living' 3D Models From Still Images
Forget animated faces and deepfake videos, researchers have unveiled a new artificial intelligence method for generating 'living,' walking 3D models using existing individual still images. The technology paves the way for interactive museum showcases and more, requiring only a single still image, painting, or even cartoon doodle featuring a reasonably clear subject in order to work.
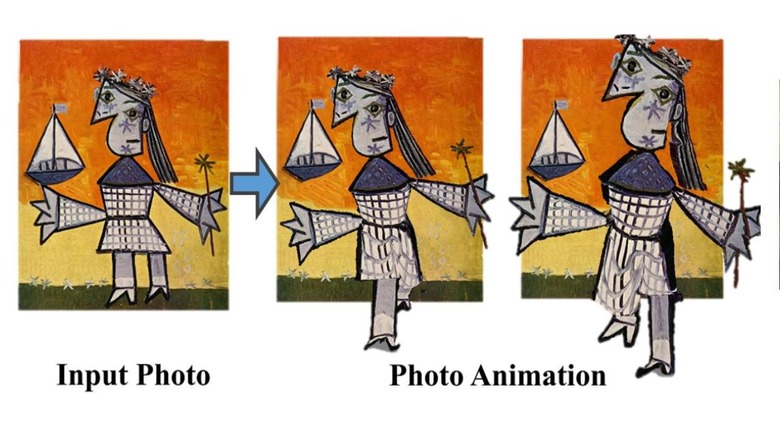
Creating a 3D model from still images generally requires multiple photos showing the subject from multiple angles. Researchers with Facebook and the University of Washington have developed an AI method that gets around that restriction, making it possible to generate a fairly accurate 3D model from a single still image featuring only one camera angle of the subject.
The Photo Wake-Up algorithm works by identifying the person (or cartoon) in the image, then masking it to separate it from the rest of the image. That masked subject has a 3D template applied to it, which is then projected back into 2D. The texture from the image (the colors) are applied to this 3D template, a back for the model is generated based on the data from the image, and then the two are stitched to create a proper 3D model.
The result is a 3D model that can be animated to walk, run, sit or jump in 3D space. The model appears to peel out of the input image, which is automatically edited to fill in the void where the subject had originally been located.
The models aren't entirely realistic at this time — some of them resemble old Nintendo 64 game characters — but it's no less impressive, particularly with simple artwork. The technology could be used in a number of applications, including augmented reality, to bring photos and artwork to life. A museum, for example, may use the technology with an app to provide visitors with an interactive look at popular content.
There are some limitations at this time, however, including that Photo Wake-Up works best with images that show the subject from the front. Of note, the AI is able to handle some images where an arm is bent in front of the body, animating that limb so that it moves naturally, but the researchers say the method can't yet handle crossed legs or subjects where a large part of the body is blocked.