Hallucinating AIs Could Produce The Perfect Robot Maid
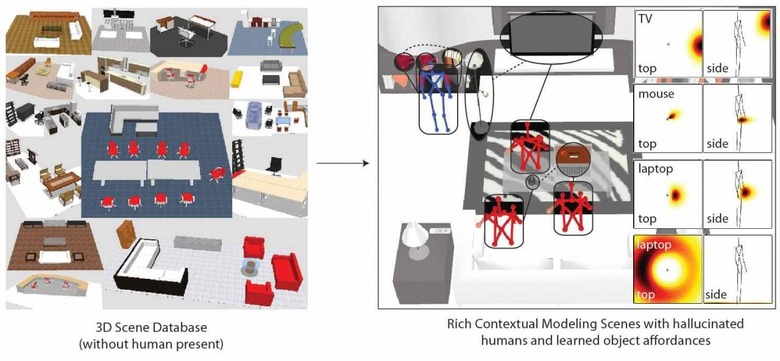
Robots that hallucinate humans to better understand a 3D space could one day lead to artificial intelligence not only better equipped to cohabit with us, but to autonomously navigate and interact with new environments. The research, "Hallucinating Humans for Learning Object Affordances" by the Personal Robotics Lab team at Cornell, posits that, for robots to understand the environments they're deployed in, they must model how humans use them. By mapping in imaginary humans – sitting, standing, and in other common poses – the robots showed they were better able to organize objects in the best ways for people to use them.
"Humans cast a substantial influence on their en- vironments by interacting with it" the researchers argue. Therefore, even though an environment may physically contain only objects, it cannot be modeled well without considering humans."
Considering how humans would typically interact with their environment can be a shortcut to understanding the objects in a room, for instance. Asked to locate a monitor, as an example, an AI that knew that a desktop would be a likely place, and at a certain height, would know to look there more closely. "If it is asked to place a mouse," the research continues, "considering how humans interact with the mouse and monitor, it would put it at accessible places such as the right front of the monitor."
Of course, actually reaching that point of understanding takes some work, and the Cornell team uses "infinite latent conditional random fields" (ILCRF) which model multiple different possibilities of interaction simultaneously and gage their likelihood. So, the robot understands human reach and how having objects – such as a mug – within the sweep of an arm using a mouse would be counterproductive as it could lead to accidents. Similarly, the knowledge that most humans are right-handed would be used to place a mouse in the position most likely to be useful to most users.
The proof of the pudding was in the success of the robots interactivity, with the AI's better able to infer potential human poses and arrangements of objects in real scenes than counterparts without the ILCRF system.
The upshot might be robots that can be deployed into new environments without any prior explanation of layout or mapping data, and left to negotiate the area in more intelligent ways. A domestic 'bot could then better arrange your belongings, perhaps: putting the TV remote on the coffee table, within easier reach of the couch, rather than by the TV itself, where a less human-aware object matching process might assume the best location would be.
VIA PhysOrg; IEEE Spectrum