Google Makes Parsey McParseface Language Tool Open Source

Google has released SyntaxNet, a natural-language neural network framework for helping machines understand natural language, as an open-source offering. Says Google, the open-sourced SyntaxNet include Parsey McParseface, a language parser trained to dissect English, and "all the code needed" for training SyntaxNet with one's own data. According to Google, this is the most accurate parser in the world.
SyntaxNet and Parsey McParseface is part of a Natural Language Understanding (NLU) system, which takes a sentence and parses it (sort of like those sentences you had to diagram in grade school) into its various parts, such as nouns, verbs, and adjectives. For natural language researchers and those with needs for such an application, the release is a huge boon to the field.
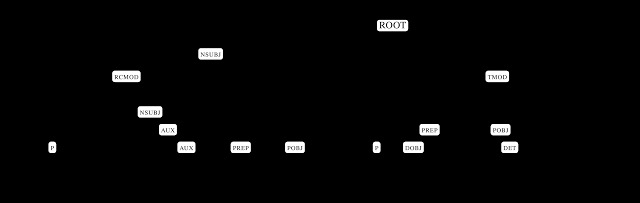
By splitting a language up into its constituent parts, the software can then discern the meaning of the sentence as a whole, something essential for understanding 'natural' language sentences and commands. This is no small task for machines — so-called natural language is composed of sentences that can be highly ambiguous, meandering, and formed in a variety of different ways while conveying generally the same intent or meaning.
Humans, of course, are very apt at dealing with these ambiguities for a variety of reasons: being familiar with common sentences structures and ways things are phrased, having the ability to compare a meaning in context to see if it fits, and, of course, being able to ignore absurd and nonsensical interpretations.
To deal with that ambiguity, SyntaxNet gives the machines an ability to understand the intended meaning via neural networks — for English, sentences are processed starting from the left and working right, with different possibilities being considered and ranked until a final understanding is formed.
According to Google, Parsey McParseface — trained with TensorFlow framework — is one "of the most complex networks" it has produced. In one test, they found the model to have more than a 94-percent accuracy level, while it is generally accepted that trained linguists have a 96 – 97-percent accuracy at these tasks...making the software nearly as skilled as humans.
SyntaxNet is available via Github; those more interested in the technology itself can check out Google's paper here.
SOURCE: Google Research Blog