DeepMind AlphaStar AI Beats StarCraft II Pro Players 10-1
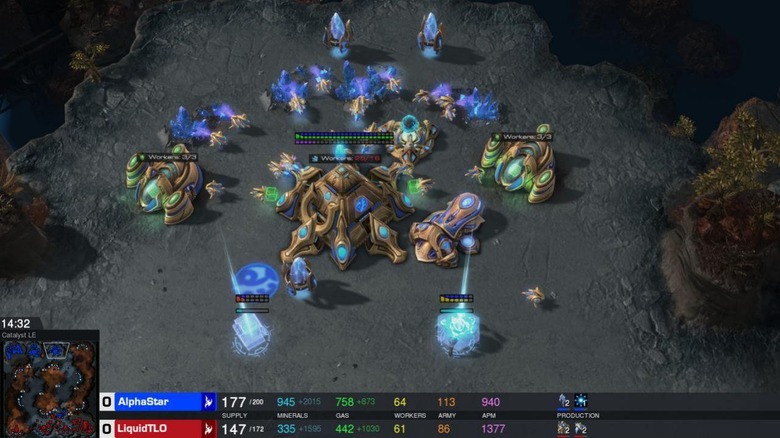
As if it weren't enough that an AI has been beating humans at a game that is considered part strategy but mostly memorization of strategies, now an AI is also beating them at a game that requires quick strategic thinking and quick mouse-clicking. Of course, the former is probably too easy for a computer to do, since it requires no fingers, but DeepMind's new AlphaStar AI has beaten human pros at StarCraft II ten times before finally letting the organics win at least once.
StarCraft II may be a strange game to pick but not only is it still popular, it is still considered to be one of the more challenging real-time strategy (RTS) games of all time. As such, it was the perfect game to test an AI's learning and decision-making capabilities. And to help it prove or disprove AlphaStar's abilities, DeepMind enlisted Blizzard's help as well as two of the world's top StarCraft II players, Dario "TLO" Wünsch and Grzegorz "MaNa" Komincz, the latter rated to be one of the best of the best.
The way that AlphaStar learned to play the game before each match is quite interesting. It started by analyzing replays of human matches to study them. It then forked (created multiple versions of itself) to generate new virtual players that specialized in different strategies and fought against each other. Of course, in the end, the AlphaStar AI learned from all of these. DeepMind then picked five agents for each of the two matches it thought had the best chance of winning against the humans.
You might think that AlphaStar would have a sort of home court advantage in a computer game. It did, after all, take just one week to "play" years' worth of matches in order to learn. And it did have the advantage of not having to focus on a single section of the map at a time, unlike the way human eyes and brains work. That said, it was still subject to regular game rules like fog of war and its reaction time was throttled to a speed slower than pros. It was even observed to have performed fewer but more efficient actions that humans did.
In the end, AlphaStar won against both TLO and MaNa in five-game matches. But to make things even more interesting, DeepMind tweaked AlphaStar to limit its focusing capability so that it had it to decide what to focus on, just like a human. It learned that new skill in a week but didn't have time to practice, and it was only then that MaNa scored its one and only victory for humanity.