Researchers Teach Robots To Move More Like Animals
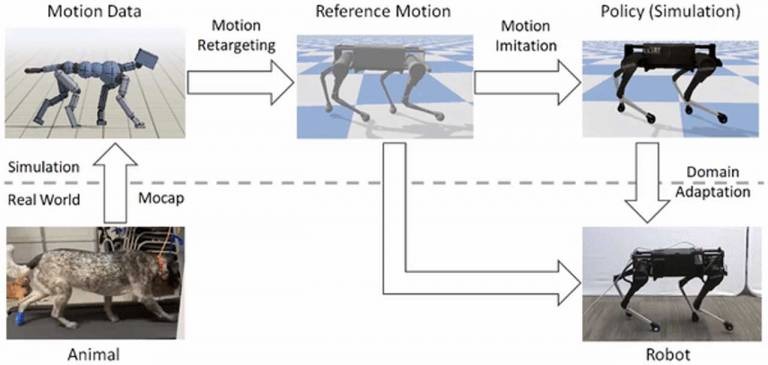
Anyone who has a pet knows that animals are very agile. Some of the things they're able to do are very impressive. A group of researchers at the Berkeley Artificial Intelligence Research (BAIR) laboratory at Berkeley are trying to teach robots to move like animals. The scientists say that they have presented a framework for learning robotic locomotion skills by imitating animals.Using a reference motion clip recorded of an animal, the framework uses reinforcement learning to train a control policy that enables a robot to imitate the motion in the real world. By providing the system with different reference motions, the team can train a quadruped robot to perform a diverse set of agile behaviors.
The behaviors the robot learned range from fast walking gates to dynamic hops and turns. Policies for the robots are initially trained in a simulated environment, and then the training is transferred to the real world using a latent space adaption technique. That technique can efficiently adapt a policy using a limited amount of data from the real robot.
Scientists say that the framework has three main components, including motion retargeting, motion imitation, and domain adaptation. The first step using a given reference motion is to create motion retargeting stage map that retargets the motion from the original animal's morphology to the robot morphology. The next step is the motion imitation stage and uses the retargeted reference motion to train a policy for imitating the motion in a simulated environment. The last step is the domain adaptation stage that transfers the policy from simulation to the real robot via a sample efficient domain adaptation process.
The team notes that simulators generally provide only a coarse approximation of the real world. Therefore, policies trained in simulation often perform poorly in the real world. The transfer policy traded simulation to the real world, the team used a sample efficient domain adaptation technique to adapt the policy to the real world using only a small number of trials on the real robot. That technique was able to adapt what was initially a poor performing scenario that led to the robot falling over to a scenario where the robot was stable. The result was a much faster and more fluid moving robot.