Punycode Phishing Attacks Exploit Unicode's Strength
In the past, it was easy to detect a fake website address designed to scam unsuspecting users. At least if you have a keen eye and a cautious mind. Now, however, it has just gotten harder to detect such phishing attacks with just your eyes. To make matters worse, even browsers are no help at all. These "homograph" phishing URLs, for all intents and purposes, looks exactly like a regular, safe URL. Except they arent't. And, unfortunately, they are taking advantage of the fact that computers these days can display more languages and characters than you might even be aware of.\
The Internet has made the world a smaller place and has, therefore, made it imperative that computers support more than just the limited character set of the English language. The Unicode standard wad developed to go beyond the old ASCII character set to include all sorts of characters, symbols, and even emojis. But that same feature can also be used to dupe even the most careful computer users into visiting malicious links or entering private information in what they think are secure websites.
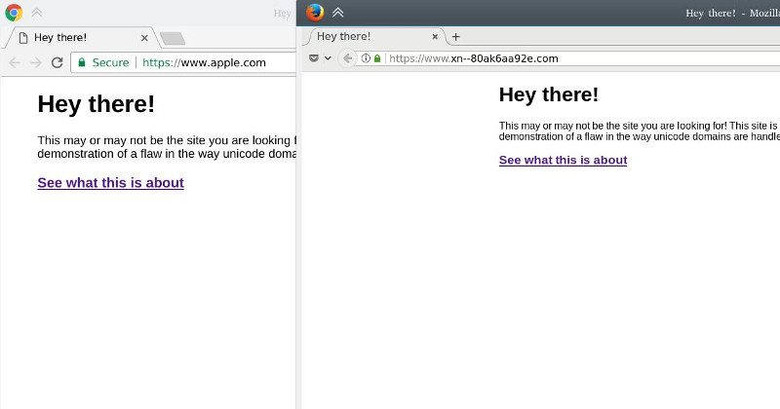
This new type of attack takes advantage of the fact that some characters from other languages are visually indistinguishable from characters in the English alphabet. For example, the Cyrillic "a", which has a Unicode number of U+0430, looks exactly like the ASCII "a", or U+0061. It has been possible to register domain names that use those homograph letters. Normally, they'd be represented in ASCII. For example, an "apple.com" that used the Cyrillic "a" would actually be written as "xn--pple-43d.com" when registered.
Complicating matters, however, is the fact that browsers would "properly" display the actual Unicode equivalent, which would make that URL above really look like "apple.com". They do protect against such potential phishing scams but with one very critical flaw. When the fake URL only includes one punycode character, the browser will flag it as potentially dangerous. However, when all the letters of the URL are actually Unicode equivalents from a another language, browsers will presume it's a legit URL from a country that uses those characters. In other words, browsers have no way to know that the Cyrillic "www.xn--80ak6aa92e.com" is actually trying to fake the real "www.apple.com".
The somewhat good news is that browser makers have been made aware of this and have implemented fixes, though not in the same way. Chrome, starting version 58, protects against homograph attacks. Firefox, however, believes that it is the domain registrar's responsibility to check for this potential scams. It does, however, have a hidden setting to show punycode by default. Opera, Internet Explorer, and Microsoft Edge are so far silent on the matter.
SOURCE: Xudong Zheng