Google Is Indexing Images From PDF Files
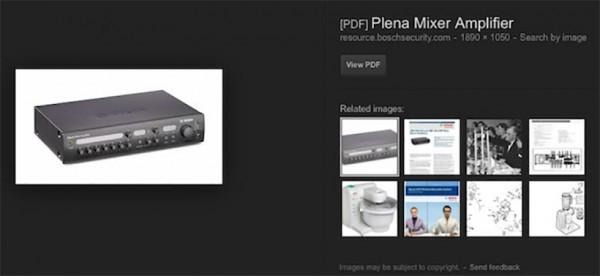
It's no secret that Google wants to index everything that is attached to the internet. The search giant spends huge sums of money in an effort to optimize its indexing capabilities. It appears that Google is now indexing images that come from scanned PDF files.
When images in the image search section of the Google search engine come from a PDF, they are marked with the PDF on the image. A link that will take you directly to the PDF the image came from is listed right alongside it.
The reason for that link is that there is no way to link directly to an image file on a PDF, so all you can do is see the image preview and then hit the PDF to view the actual image. Google has been using OCR tech since 2008 to index scanned text from PDF files.
Extracting images and making the images searchable is the next step in making PDFs searchable. Google's OCR technology recognizes over 200 languages from around the world. Google says that with 200 languages now supported by its OCR tech, all the major languages in the world are supported.
SOURCE: GoogleSystem