Facebook Uses AI To Improve Photo Descriptions For The Visually Impaired
One of the most common types of content shared on Facebook, and other social media platforms are photographs. While most social media users can look at an image and see what it represents, it's not so easy for those who are blind or visually impaired. Facebook says screen readers can describe the contents of these images using a synthetic voice allowing blind or visually impaired users to understand images in the Facebook feed.
However, many photos are posted without alt text leading to Facebook's introduction of automatic alternative text (AAT) in 2016. That technique uses object recognition to generate descriptions of photos on demand for blind or visually impaired users. Since 2016 Facebook has been working to improve AAT and recently unveiled the next generation of the technology.
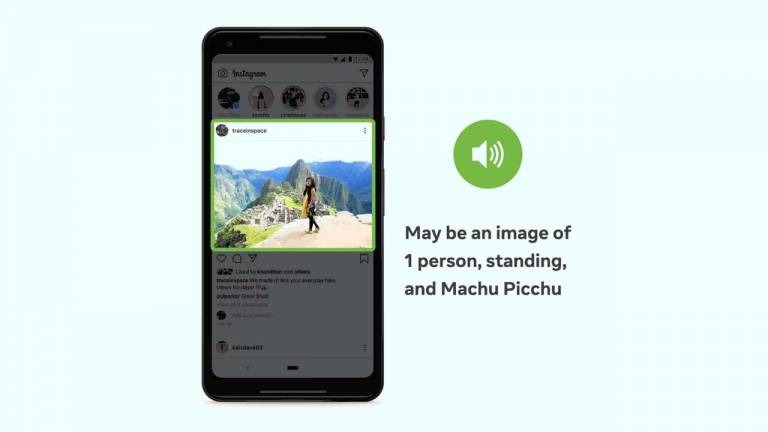
The latest advancement improves the photo experience for users with an expanded number of concepts AAT can reliably detect and identify in a photo by more than ten times. That means there are fewer photos without a description, and the descriptions offered are more detailed. AAT can offer descriptions with the ability to identify activities, landmarks, types of animals, and more.
AAT will now give descriptions such as, "May be a selfie of two people, outdoors, the Leaning Tower of Pisa." Facebook also says the ability to include information about the potential location and relative size of elements in a photo is an industry first. Rather than simply saying, "May be an image of five people," it can specify two people in the center of the photo and three others scattered towards the fringes.
Facebook says the advancements helps users who are blind or visually impaired better understand what's in photos posted by family and friends. The latest version of AAT uses a model trained on weakly-supervised data in the form of billions of public Instagram images and hashtags. Models resulting from the training are more accurate and more culturally and demographically inclusive. The improved AAT reliably recognizes over 1200 concepts.